Architecting a Headless CMS Frontend: Principles, Patterns, and Pitfalls
After implementing headless CMS architectures across multiple production systems, I've learned that success hinges on understanding three core patterns and avoiding five common pitfalls.

Why Teams Choose Headless (And Why It Matters)
Headless CMS architectures decouple content management from presentation, exposing content via APIs rather than rendering pages server-side. We see teams adopting this approach for three main reasons: multi-channel content delivery becomes trivial, performance improves dramatically through static generation and edge caching, and developer velocity increases when frontend teams can iterate independently.
The fundamental shift is architectural: content becomes data, not markup. This enables powerful patterns like content reuse across touch points, programmatic content manipulation, and sophisticated caching strategies that traditional CMS platforms struggle with.

The key insight is that your mobile app, frontend website, and third-party integrations all use the same content APIs. This means:
Single source of truth for all content
Consistent data structure across all touch points
Reduced maintenance - one API to rule them all
Future-proof - new integrations use existing APIs
Real-World Example:
Imagine an e-commerce company where:
Frontend website displays product pages
Mobile app shows the same products
Email marketing pulls product descriptions for campaigns
Analytics dashboard tracks content performance
Customer support accesses product specs for help tickets
All these systems hit the same headless CMS APIs, ensuring consistency and reducing the integration burden.
This is the core value proposition of headless CMS: write content once, distribute everywhere through APIs.
Three Core Architecture Patterns That Work
Pattern 1: Hybrid Rendering Strategy
Don't choose between static and dynamic—use both strategically. Different content types have different requirements.
// Match rendering strategy to content characteristics
function getRevalidationStrategy(contentType: string): number {
const strategies = {
'marketing-page': 86400, // 24 hours - rarely changes
'blog-post': 3600, // 1 hour - occasional updates
'product-info': 1800, // 30 minutes - price changes
'news': 300, // 5 minutes - breaking updates
};
return strategies[contentType] || 3600;
}
The key insight: content update frequency should drive your caching strategy, not technology preferences. Marketing pages can be static for days, while product prices need frequent updates.
Pattern 2: Type-Safe Content Contracts
Runtime validation prevents malformed content from breaking your application. The architecture pattern is validation at the boundary, not throughout your app.
// Validate once at the API boundary
const ContentSchema = z.object({
type: z.enum(['hero', 'text', 'image', 'cta']),
metadata: z.object({
publishedAt: z.iso.datetime(),
author: z.string(),
}),
});
// Your app works with validated types everywhere else
type Content = z.infer<typeof ContentSchema>;
Architectural decision: Fail fast at the data boundary rather than handling invalid content throughout your component tree.
Pattern 3: Component-Driven Content Architecture
Map CMS content blocks to React components for flexible page building. The pattern is about separation of concerns—content structure drives component selection.
// Content drives component selection
const componentMap = {
hero: HeroComponent,
text: TextBlock,
image: ImageBlock,
cta: CallToAction,
};
function renderContentBlock(block: ContentBlock) {
const Component = componentMap[block.type];
return Component ? <Component {...block.props} /> : null;
}
Key architectural insight: Let content authors compose pages by selecting component types, not by writing HTML or choosing layouts.
Five Common Pitfalls (And How to Avoid Them)
1. Vendor Lock-in Through Proprietary APIs
The Problem: CMS vendors provide convenient SDKs that create subtle dependencies on their specific implementations.
The Solution: Abstract CMS interactions behind your own interfaces.
// Create vendor-agnostic contracts
interface ContentRepository {
fetchContent(id: string): Promise<ContentBlock>;
searchContent(query: string): Promise<ContentBlock[]>;
}
// Implementation can be swapped without changing your app
class ContentfulRepository implements ContentRepository {
async fetchContent(id: string): Promise<ContentBlock> {
const entry = await this.client.getEntry(id);
return this.transformToContentBlock(entry);
}
}
Architectural insight: The repository pattern isn't just good practice—it's insurance against vendor changes and migration nightmares.
2. Overfetching Without Realizing It
The Problem: GraphQL doesn't automatically prevent overfetching—poorly designed queries can request unnecessary data.
The Solution: Design component-specific fragments, not kitchen-sink queries.
// Bad: Everything for everyone
const KITCHEN_SINK_QUERY = gql`
query GetPost($id: ID!) {
post(id: $id) {
title content author { name bio avatar socialLinks }
seo { title description keywords }
analytics { views shares }
}
}
`;
// Good: Component-specific needs
const POST_SUMMARY_FRAGMENT = gql`
fragment PostSummary on Post {
title excerpt publishedAt
author { name avatar }
}
`;
Key decision: Optimize for component requirements, not data availability.
3. Ignoring Content Author Experience
The Problem: Technical teams focus on developer experience and forget that content authors need to use the system daily.
The Solution: Treat preview functionality as a first-class feature, not an afterthought.
// Preview mode should be reliable, not fragile
export async function generatePreviewData(request: NextRequest) {
const { searchParams } = new URL(request.url);
const secret = searchParams.get('secret');
if (secret !== process.env.PREVIEW_SECRET) {
return new Response('Invalid token', { status: 401 });
}
// Always fetch fresh content for previews
const content = await fetchDraftContent(slug, { cache: 'no-store' });
return NextResponse.redirect(new URL(`/preview/${slug}`, request.url));
}
Critical insight: If content authors can't trust preview mode, they'll stop using your headless system.
4. Underestimating Build Time Impact
The Problem: Static generation sounds great until your build times hit 20+ minutes and block deployments.
The Solution: Implement on-demand revalidation instead of rebuilding everything.
// Revalidate specific content, not entire site
export async function POST(request: Request) {
const { contentId, contentType } = await request.json();
try {
// Surgical cache invalidation
await revalidateTag(`content-${contentType}-${contentId}`);
return Response.json({ revalidated: true });
} catch (err) {
return Response.json({ revalidated: false });
}
}
Architectural decision: Plan for content velocity from day one, not when builds start timing out.
5. Poor Error Boundaries for Content Failures
The Problem: One malformed content block breaks the entire page, creating a terrible user experience.
The Solution: Implement granular error boundaries around content components.
// Isolate content rendering failures
function ContentBlockErrorBoundary({ children, fallback }) {
return (
<ErrorBoundary
fallback={fallback}
onError={(error) => {
// Log but don't crash the page
console.error('Content block failed:', error);
}}
>
{children}
</ErrorBoundary>
);
}
Critical pattern: Content failures should degrade gracefully, not cascade through your entire application.
Content Deployment Pipeline
Understanding the technical patterns is only half the battle. Successful headless CMS implementations require robust deployment workflows that content teams can trust. Here's the pipeline we've refined across multiple production deployments:
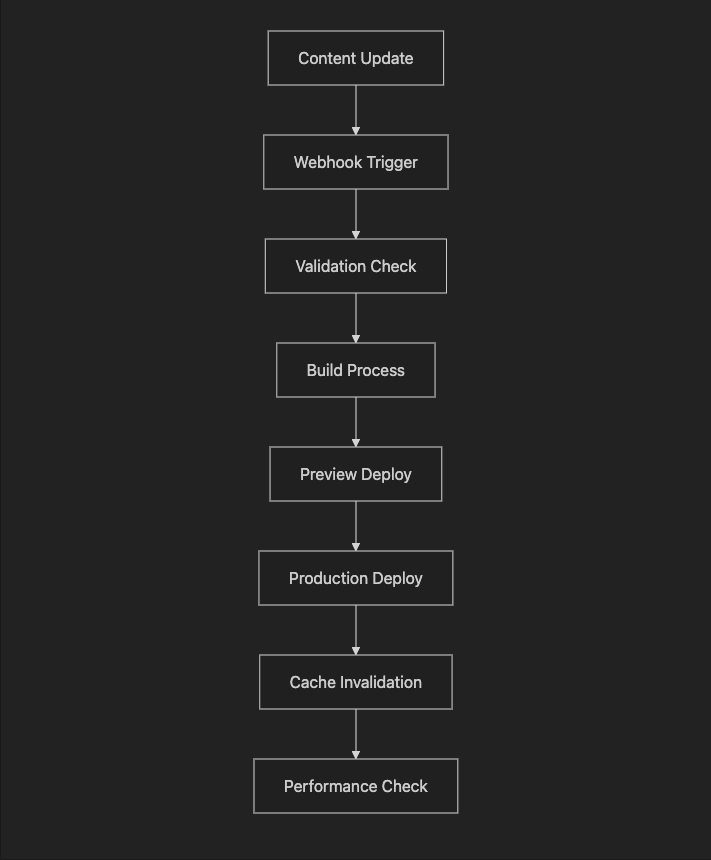
A → B: Content Update → Webhook Trigger
Content authors publish changes in the CMS, automatically triggering webhooks to your build system. This eliminates manual deployment steps and ensures content changes flow through your pipeline consistently.
B → C: Webhook Trigger → Validation Check
Validate incoming content before processing. Check for required fields, schema compliance, and content structure. This prevents malformed content from breaking your build process—a critical step that many teams skip until they get burned.
C → D: Validation Check → Build Process
If validation passes, trigger your build or regeneration process. The key architectural decision here: full rebuild vs. incremental updates based on content type and change scope.
D → E: Build Process → Preview Deploy
Deploy to a staging environment first. This step is non-negotiable for content team confidence. If content authors can't reliably preview their changes, they'll lose trust in your headless system.
E → F: Preview Deploy → Production Deploy
After preview approval, deploy to production. This can be automatic for low-risk content types or require manual approval for critical pages. Design this step based on your organization's risk tolerance.
F → G: Production Deploy → Cache Invalidation
Clear CDN caches for updated content paths. The architectural challenge: invalidate only what changed to maintain performance while ensuring content freshness.
G → H: Cache Invalidation → Performance Check
Monitor Core Web Vitals and load times after deployment. This feedback loop catches performance regressions and validates that your caching strategy is working as intended.
Pipeline insight: Each step addresses a common failure point in headless implementations. The diagram shows why preview functionality and build time considerations—two of our biggest pitfalls—are architectural requirements, not nice-to-haves.
Summary
Successful headless CMS implementations come down to three core patterns: hybrid rendering strategies that match content characteristics, type-safe content contracts that prevent runtime failures, and component-driven architectures that enable flexible content creation.
The biggest pitfalls aren't technical—they're organizational. Vendor lock-in, poor author experience, and inadequate error handling cause more headless CMS failures than architectural decisions. Plan for these human factors as carefully as you plan your component hierarchies.
Key insight: Headless CMS success depends as much on content team workflows as technical architecture. The best pattern libraries in the world won't save you if your content authors can't effectively use the system.
Start with solid foundations—runtime validation, error boundaries, and preview workflows—then optimize for performance. Your content team will thank you, and your architecture will scale gracefully as requirements evolve.
Additional References
Headless CMS Platforms & Documentation:
Contentful Documentation: Comprehensive API documentation and best practices
Strapi Documentation: Open-source headless CMS implementation guide
Sanity Documentation: Real-time collaborative editing and flexible content modeling
Frontend Framework Integration:
Next.js Data Fetching: SSG, SSR, and ISR implementation patterns
SvelteKit Loading Data: Svelte patterns for data fetching and rendering
Performance & Validation:
Zod Documentation: Runtime schema validation for API responses
TanStack Query Documentation: Advanced caching and data synchronization
Core Web Vitals Guide: Performance metrics that matter for headless sites
About Me
Engineering Leader with a decade of experience building scalable frontend architectures for high-traffic applications. Specialized in headless CMS implementations, performance optimization, and developer experience tooling. Currently architecting content delivery systems that serve millions of users while maintaining exceptional developer productivity.
Passionate about sharing real-world engineering lessons learned from production deployments, code reviews, and the inevitable 2 AM debugging sessions that teach us the most.
Connect with me:
LinkedIn: linkedin.com/in/stanleyjnadar
Twitter: @istealersn_dev
Dev.to: dev.to/istealersn_dev
Follow for more insights on frontend architecture, headless CMS patterns, and battle-tested engineering practices that actually work in production.